从文件中取数据
Kotlin Notebook, coupled with the Kotlin DataFrame library, enables you to work with both non-structured and structured data. This combination offers the flexibility to transform non-structured data, such as data found in TXT files, into structured datasets.
For data transformations, you can use such methods as add, split,
convert, and parse.
Additionally, this toolset enables the retrieval and manipulation of data from various structured file formats,
including CSV, JSON, XLS, XLSX, and Apache Arrow.
In this guide, you can learn how to retrieve, refine, and handle data through multiple examples.
Before you start
Kotlin Notebook relies on the Kotlin Notebook plugin, which is bundled and enabled in IntelliJ IDEA by default.
If the Kotlin Notebook features are not available, ensure the plugin is enabled. For more information, see Set up an environment.
Create a new Kotlin Notebook:
- Select File | New | Kotlin Notebook.
In the Kotlin Notebook, import the Kotlin DataFrame library by running the following command:
%use dataframe
Retrieve data from a file
To retrieve data from a file in Kotlin Notebook:
- Open your Kotlin Notebook file (
.ipynb). Import the Kotlin DataFrame library by adding
%use dataframein a code cell at the start of your notebook.Make sure to run the code cell with the
%use dataframeline before you run any other code cells that rely on the Kotlin DataFrame library.Use the
.read()function from the Kotlin DataFrame library to retrieve data. For example, to read a CSV file, use:DataFrame.read("example.csv").
The .read() function automatically detects the input format based on the file extension and content.
You can also add other arguments to customize the function, such as specifying the delimiter with delimiter = ';'.
For a comprehensive overview of additional file formats and a variety of read functions, see the Kotlin DataFrame library documentation.
Display data
Once you have the data in your notebook, you can easily store it in a variable and access it by running the following in a code cell:
val dfJson = DataFrame.read("jsonFile.json")
dfJson
This code displays the data from the file of your choice, such as CSV, JSON, XLS, XLSX, or Apache Arrow.
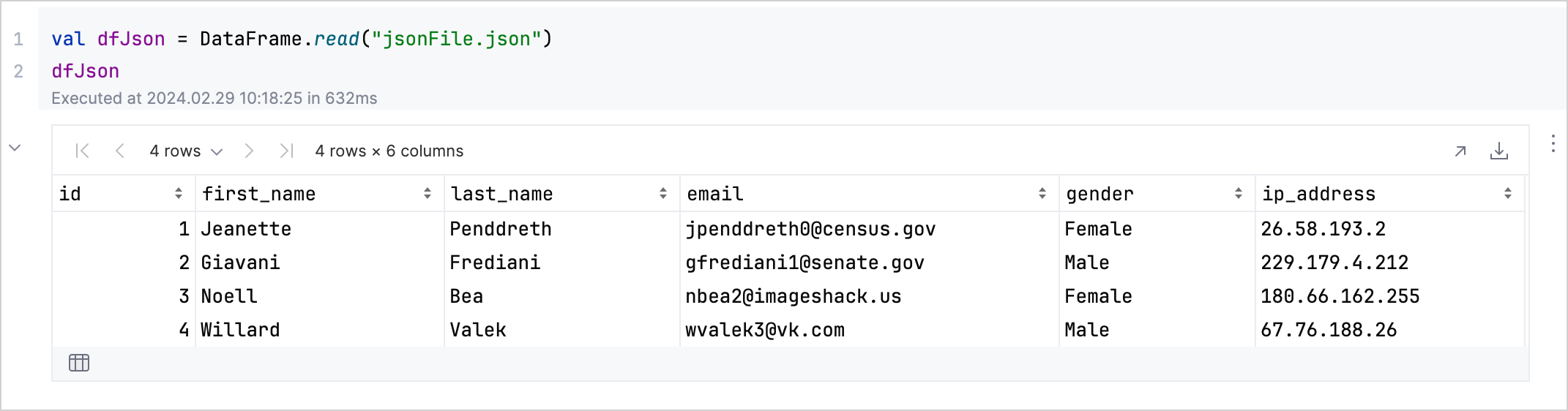
To gain insights into the structure or schema of your data, apply the .schema() function on your DataFrame variable.
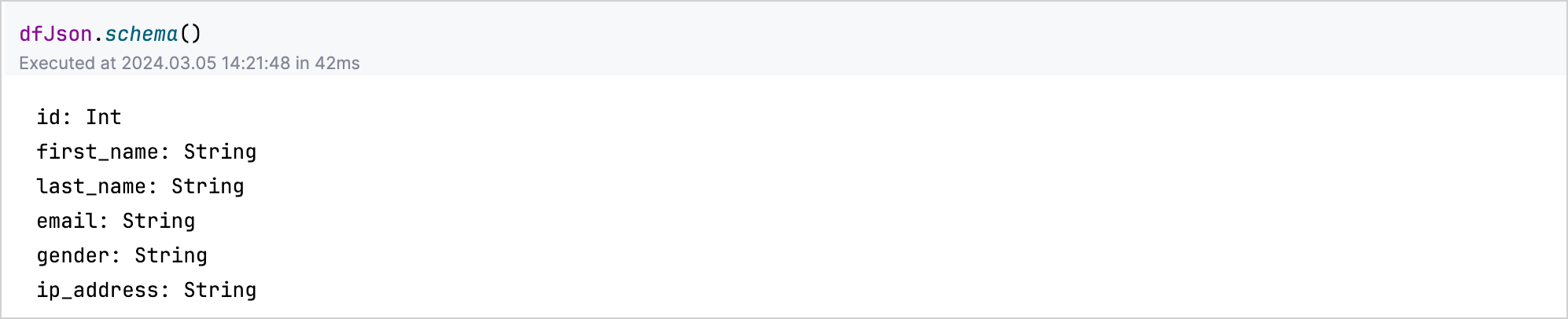
For example, dfJson.schema() lists the type of each column in your JSON dataset.
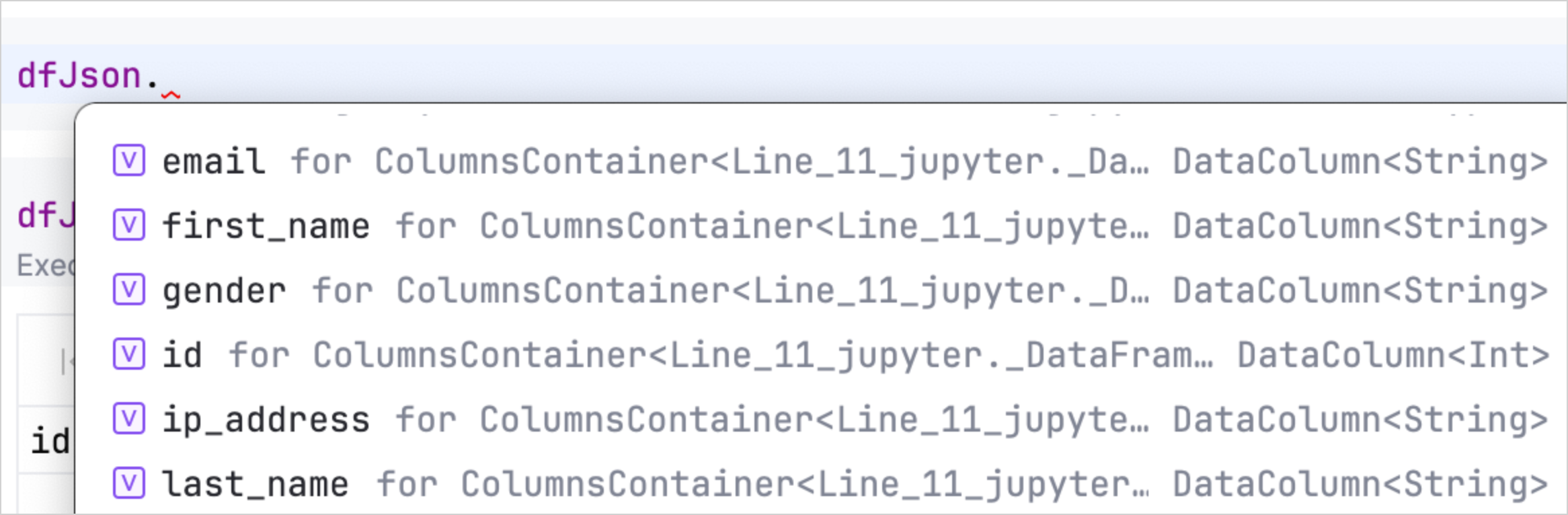
You can also use the autocompletion feature in Kotlin Notebook to quickly access and manipulate the properties of your DataFrame. After loading your data, simply type the DataFrame variable followed by a dot to see a list of available columns and their types.
Refine data
Among the various operations available in the Kotlin DataFrame library for refining your dataset, key examples include grouping, filtering, updating, and adding new columns. These functions are essential for data analysis, allowing you to organize, clean, and transform your data effectively.
Let's look at an example where the data includes movie titles and their corresponding release year in the same cell. The goal is to refine this dataset for easier analysis:
Load your data into the notebook using the
.read()function. This example involves reading data from a CSV file namedmovies.csvand creating a DataFrame calledmovies:val movies = DataFrame.read("movies.csv")Extract the release year from the movie titles using regex and add it as a new column:
val moviesWithYear = movies .add("year") { "\\d{4}".toRegex() .findAll(title) .lastOrNull() ?.value ?.toInt() ?: -1 }Modify the movie titles by removing the release year from each title. This cleans up the titles for consistency:
val moviesTitle = moviesWithYear .update("title") { "\\s*\\(\\d{4}\\)\\s*$".toRegex().replace(title, "") }Use the
filtermethod to focus on specific data. In this case, the dataset is filtered to focus on movies that were released after the year 1996:val moviesNew = moviesWithYear.filter { year >= 1996 } moviesNew
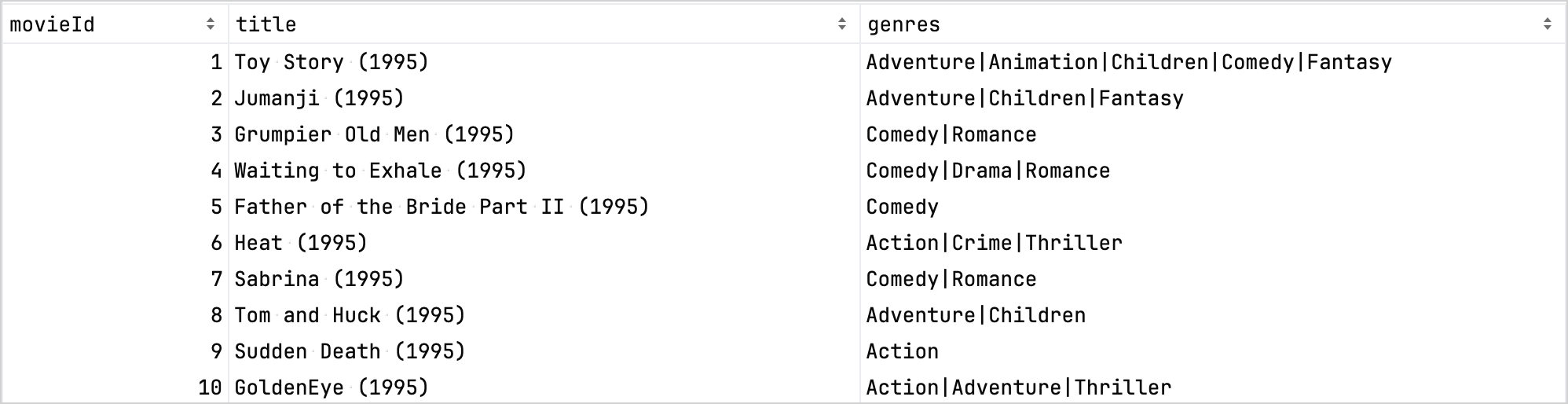
For comparison, here is the dataset before refinement:
The refined dataset:
This is a practical demonstration of how you can use the Kotlin DataFrame library's methods, like add, update, and filter to
effectively refine and analyze data in Kotlin.
For additional use cases and detailed examples, see Examples of Kotlin Dataframe.
Save DataFrame
After refining data in Kotlin Notebook using the Kotlin DataFrame library, you can easily export your processed
data. You can utilize a variety of .write() functions for this purpose, which support saving in multiple formats,
including CSV, JSON, XLS, XLSX, Apache Arrow, and even HTML tables.
This can be particularly useful for sharing your findings, creating reports, or making your data available for further analysis.
Here's how you can filter a DataFrame, remove a column, save the refined data to a JSON file, and open an HTML table in your browser:
In Kotlin Notebook, use the
.read()function to load a file namedmovies.csvinto a DataFrame namedmoviesDf:val moviesDf = DataFrame.read("movies.csv")Filter the DataFrame to only include movies that belong to the "Action" genre using the
.filtermethod:val actionMoviesDf = moviesDf.filter { genres.equals("Action") }Remove the
movieIdcolumn from the DataFrame using.remove:val refinedMoviesDf = actionMoviesDf.remove { movieId } refinedMoviesDfThe Kotlin DataFrame library offers various write functions to save data in different formats. In this example, the
.writeJson()function is used to save the modifiedmovies.csvas a JSON file:refinedMoviesDf.writeJson("movies.json")Use the
.toStandaloneHTML()function to convert the DataFrame into a standalone HTML table and open it in your default web browser:refinedMoviesDf.toStandaloneHTML(DisplayConfiguration(rowsLimit = null)).openInBrowser()
下一步做什么
- Explore data visualization using the Kandy library
- Find additional information about data visualization in Data visualization in Kotlin Notebook with Kandy
- For an extensive overview of tools and resources available for data science and analysis in Kotlin, see Kotlin and Java libraries for data analysis